Статистические методы локального поиска
Статистические методы или методы случайного поиска получили достаточно широкое распространение при построении оптимальных решений в различных приложениях. Это объясняется в первую очередь тем, что с ростом размерности задач резко снижается эффективность регулярных методов поиска (детерминированных): так называемое “проклятие размерности”. Во-вторых, зачастую информация об оптимизируемом объекте слишком мала для того, чтобы можно было применить детерминированные методы. Достаточно часто статистические алгоритмы используют при поиске оптимального решения в системах управления, когда отклик системы можно получить только при задании управляющих воздействий ![]() на ее входах. В таких ситуациях статистические алгоритмы могут оказаться значительно эффективнее детерминированных.
на ее входах. В таких ситуациях статистические алгоритмы могут оказаться значительно эффективнее детерминированных.

Рис.
Наибольший эффект применение статистических методов приносит при решении задач большой размерности или при поиске глобального экстремума.
Под случайными или статистическими методами поиска будем понимать методы, использующие элемент случайности либо при сборе информации о целевой функции при пробных шагах, либо для улучшения значений функции при рабочем шаге. Случайным образом может выбираться направление спуска, длина шага, величина штрафа при нарушении ограничения и т.д.
Статистические алгоритмы обладают рядом достоинств:
простота реализации и отладки программ;
надежность и помехоустойчивость;
универсальность;
возможность введения операций обучения в алгоритм поиска;
возможность введения операций прогнозирования оптимальной точки (оптимального решения).
А основными недостатками являются большое количество вычислений минимизируемой функции и медленная сходимость в районе экстремума.
Принято считать, что преимущество статистических методов проявляется с ростом размерности задач, так как вычислительные затраты в детерминированных методах поиска с ростом размерности растут быстрее, чем в статистических алгоритмах.
Пусть нам необходимо решить задачу минимизации функции ![]() при условии, что
при условии, что ![]() .
.
В данной области по равномерному закону выбираем случайную точку ![]() и вычисляем в ней значение функции
и вычисляем в ней значение функции ![]() . Затем выбираем таким же образом случайную точку
. Затем выбираем таким же образом случайную точку ![]() и вычисляем
и вычисляем ![]() . Запоминаем минимальное из этих значений и точку, в которой значение функции минимально. Далее генерируем новую точку. Делаем
. Запоминаем минимальное из этих значений и точку, в которой значение функции минимально. Далее генерируем новую точку. Делаем ![]() экспериментов, после чего лучшую точку берем в качестве решения задачи (в которой функция имеет минимальное значение среди всех случайно сгенерированных).
экспериментов, после чего лучшую точку берем в качестве решения задачи (в которой функция имеет минимальное значение среди всех случайно сгенерированных).
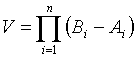 .
. 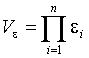 Вероятность попадания в эту окрестность при одном испытании равна
Вероятность попадания в эту окрестность при одном испытании равна ![]() . Вероятность непопадания равна
. Вероятность непопадания равна ![]() . Испытания независимы, поэтому вероятность непопадания за
. Испытания независимы, поэтому вероятность непопадания за ![]() экспериментов равна
экспериментов равна ![]() .
.
Вероятность того, что мы найдем решение за ![]() испытаний:
испытаний: ![]() .
.
Отсюда нетрудно получить оценку необходимого числа испытаний ![]() для определения минимума с требуемой точностью:
для определения минимума с требуемой точностью:
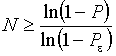 .
.
При решении экстремальных задач на областях со сложной геометрией обычно вписывают эту область в ![]() -мерный параллелепипед. А далее генерируют в этом
-мерный параллелепипед. А далее генерируют в этом ![]() -мерном параллелепипеде случайные точки по равномерному закону, оставляя только те, которые попадают в допустимую область.
-мерном параллелепипеде случайные точки по равномерному закону, оставляя только те, которые попадают в допустимую область.
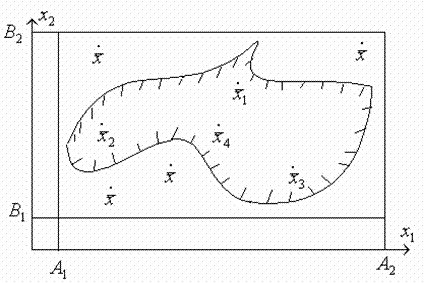
Рис.
Различают направленный и ненаправленный случайный поиск.
Ненаправленный случайный поиск. При таком поиске все последующие испытания проводят совершенно независимо от результатов предыдущих. Сходимость такого поиска очень мала, но имеется важное преимущество, связанное с возможностью решения многоэкстремальных задач (искать глобальный экстремум). Примером является рассмотренный простой случайный поиск.
Направленный случайный поиск. В этом случае отдельные испытания связаны между собой. Результаты проведенных испытаний используются для формирования последующих. Сходимость таких методов, как правило, выше, но сами методы обычно приводят только к локальным экстремумам.
Алгоритм парной пробы. В данном алгоритме четко разделены пробный и рабочий шаги.
Пусть ![]() – найденное на
– найденное на ![]() -м шаге наименьшее значение минимизируемой функции
-м шаге наименьшее значение минимизируемой функции ![]() . По равномерному закону генерируется случайный единичный вектор
. По равномерному закону генерируется случайный единичный вектор ![]() и по обе стороны от исходной точки
и по обе стороны от исходной точки ![]() делаются две пробы: проводим вычисление функции в точках
делаются две пробы: проводим вычисление функции в точках ![]() , где
, где ![]() -величина пробного шага.
-величина пробного шага.
Рабочий шаг делается в направлении наименьшего значения целевой функции. Очередное приближение определяется соотношением
![]() .
.
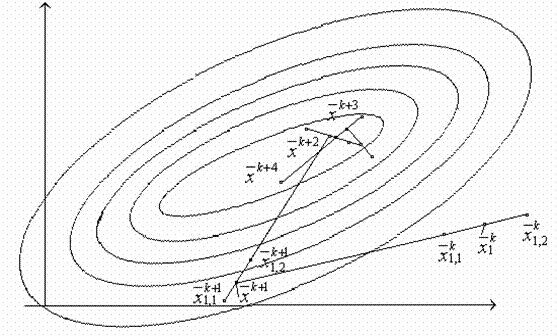
Рис.
Особенностью данного алгоритма является его повышенная тенденция к “блужданию”. Даже найдя экстремум, алгоритм может увести процесс поиска в сторону.
Алгоритм наилучшей пробы. На ![]() -м шаге мы имеем точку
-м шаге мы имеем точку ![]() . Генерируется
. Генерируется ![]() случайных единичных векторов
случайных единичных векторов ![]() . Делаются пробные шаги в направлениях
. Делаются пробные шаги в направлениях ![]() и в точках
и в точках ![]() вычисляются значения функции. Выбирается тот шаг, который приводит к наибольшему уменьшению функции:
вычисляются значения функции. Выбирается тот шаг, который приводит к наибольшему уменьшению функции: ![]() . И в данном направлении делается шаг
. И в данном направлении делается шаг
![]() .
.
Параметр ![]() может определяться как результат минимизации по направлению, определяемому наилучшей пробой, или выбираться по определенному закону.
может определяться как результат минимизации по направлению, определяемому наилучшей пробой, или выбираться по определенному закону.
С увеличением числа проб выбранное направление приближается к направлению ![]() .
.
Если функция ![]() близка к линейной, то есть возможность ускорить поиск, выбирая вместе с наилучшей и наихудшую пробу. Тогда рабочий шаг можно делать или в направлении наилучшей, или в направлении, противоположном наихудшей пробе.
близка к линейной, то есть возможность ускорить поиск, выбирая вместе с наилучшей и наихудшую пробу. Тогда рабочий шаг можно делать или в направлении наилучшей, или в направлении, противоположном наихудшей пробе.
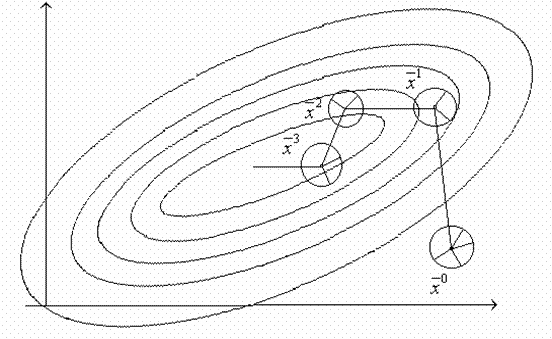
Рис.
Метод статистического градиента. Из исходного состояния ![]() делается
делается ![]() независимых проб
независимых проб ![]() в
в ![]() случайных направлениях, а затем вычисляются соответствующие значения минимизируемой функции в этих точках. Для каждой пробы запоминаем приращения функции
случайных направлениях, а затем вычисляются соответствующие значения минимизируемой функции в этих точках. Для каждой пробы запоминаем приращения функции
![]() .
.
После этого формируем векторную сумму
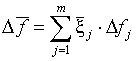 .
.
В пределе при ![]() направление
направление ![]() совпадает с направлением градиента целевой функции. При конечном
совпадает с направлением градиента целевой функции. При конечном ![]() вектор
вектор ![]() представляет собой статистическую оценку направления градиента. В направлении
представляет собой статистическую оценку направления градиента. В направлении ![]() делается рабочий шаг и, в результате, очередное приближение определяется соотношением
делается рабочий шаг и, в результате, очередное приближение определяется соотношением
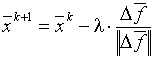 .
.
При выборе оптимального значения ![]() , которое минимизирует функцию в заданном направлении, мы получаем статистический вариант метода наискорейшего спуска. Существенное преимущество перед детерминированными алгоритмами заключается в возможности принятия решения о направлении рабочего шага при
, которое минимизирует функцию в заданном направлении, мы получаем статистический вариант метода наискорейшего спуска. Существенное преимущество перед детерминированными алгоритмами заключается в возможности принятия решения о направлении рабочего шага при ![]() . При
. При ![]() и неслучайных ортогональных рабочих шагах, направленных вдоль осей координат, алгоритм вырождается в градиентный метод.
и неслучайных ортогональных рабочих шагах, направленных вдоль осей координат, алгоритм вырождается в градиентный метод.
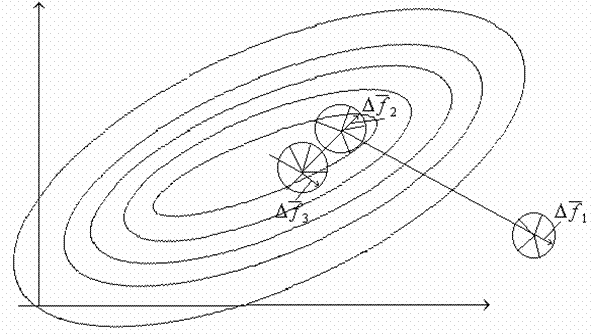
Рис.
Алгоритм наилучшей пробы с направляющим гиперквадратом. Внутри допустимой области строится гиперквадрат. В этом гиперквадрате случайным образом разбрасывается ![]() точек
точек ![]() , в которых вычисляются значения функции. Среди построенных точек выбираем наилучшую. Таким образом, на 1-м этапе координаты случайных точек удовлетворяют неравенствам
, в которых вычисляются значения функции. Среди построенных точек выбираем наилучшую. Таким образом, на 1-м этапе координаты случайных точек удовлетворяют неравенствам ![]() , и
, и ![]() – точка с минимальным значением целевой функции.
– точка с минимальным значением целевой функции.
Опираясь на эту точку, строим новый гиперквадрат. Точка, в которой достигается минимум функции на ![]() -м этапе, берется в качестве центра нового гиперквадрата на
-м этапе, берется в качестве центра нового гиперквадрата на ![]() -м этапе.
-м этапе.
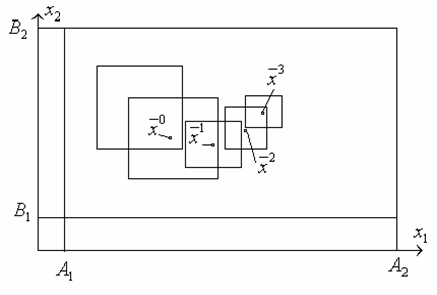
Рис.
Координаты вершин гиперквадрата на ![]() -м этапе определяются соотношениями
-м этапе определяются соотношениями
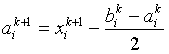 ,
, 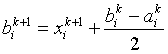 ,
,
где ![]() – наилучшая точка в гиперквадрате на
– наилучшая точка в гиперквадрате на ![]() -м этапе.
-м этапе.
В новом гиперквадрате выполняем ту же последовательность действий, случайным образом разбрасывая ![]() точек. В результате осуществляется направленное перемещение гиперквадрата в сторону уменьшения функции.
точек. В результате осуществляется направленное перемещение гиперквадрата в сторону уменьшения функции.
В алгоритме с обучением стороны гиперквадрата могут регулироваться в соответствии с изменением по некоторому правилу параметра ![]() , определяющего стратегию изменения стороны гиперквадрата. В этом случае координаты вершин гиперквадрата на
, определяющего стратегию изменения стороны гиперквадрата. В этом случае координаты вершин гиперквадрата на ![]() -м этапе будут определяться соотношениями
-м этапе будут определяться соотношениями
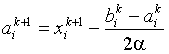 ,
, 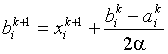 .
.
Хорошо выбранное правило регулирования стороны гиперквадрата приводит к достаточно эффективному алгоритму поиска.
В алгоритмах случайного поиска вместо направляющего гиперквадрата могут использоваться направляющие гиперсферы, направляющие гиперконусы.